前情提要:
在上一篇介紹Skip-Gram Model的文章中提到skip-gram在執行時會因為參數過多而使網絡模型變得肥大且難以訓練,尤有甚者,為了訓練參數量如此大的模型並避免過擬合over-fitting,我們需要極大的訓練樣本量。為解決這個問題,Word2Vec的作者提出了一個辦法:負採樣Negative Sampling
這個方法的創新點在於:
- 將模型中常見的單詞組合(word pairs)或者詞組作為單個字詞「words」來處理。
- 對高頻次單詞進行抽樣來減少訓練樣本的個數。
- 在最佳化過程中採用「negative sampling」,使每個訓練樣本只會更新一小部分的模型權重,從而降低計算負擔。
值得一提的是,negative sampling不僅降低計算量負擔,同時也提高了詞向量的訓練質量。
單詞組合與詞組
在很多時候個別單詞組合會產生完全不同的意思,例如"New" + “York" 或 “Boston" + “Globe"。故在執行訓練時應將其視為一個詞組而非個別單詞。在Google發布的模型中,它本身的訓練樣本中有來自Google News數據集中的1000億個單詞,但除個別單詞外,單詞組合(或詞組)又有3百萬之多。對該詞庫有興趣的原文作者另外寫了一篇介紹,詞庫則可參閱該github。
在google所發布論文的"Learning Phrase"另有說明詞組偵測如何執行,原文作者另外對其發佈之python code下了一些註解,詳此github。組合的方式其實很直觀,每次執行時只針對兩個單詞做組合,但這個步驟可以重複執行以組合成更長的詞組。如將New 跟 York組合成"New York"後再跟"City"組合成"New York City"。該執行工具會計算詞組在訓練文檔裡出現的次數並使用特定公式計算決定哪些單詞組合(word pairs)可以合併為一個詞組(phrases)。該計算式會將相對於兩個單詞個別出現更常一起出現的單詞組合合併為詞組,且偏好不常在文檔內出現的詞組以避免組合一些很常見但沒什麼太大意義的詞組如"This is"或"and the"。
對高頻單詞進行子抽樣
以上一篇介紹的訓練方式為例:
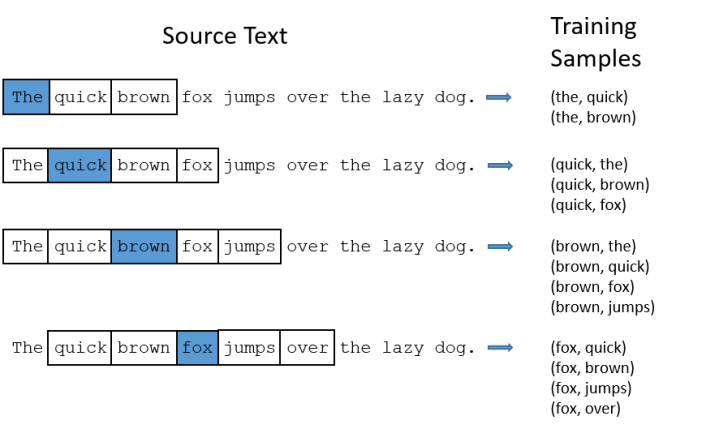
但是對於「the」這種常用高頻單詞,這樣的處理方式會存在下面兩個問題:
- 當我們得到成對的單詞訓練樣本時,(“fox", “the") 這樣的訓練樣本並不會給我們提供關於"fox"更多的語義信息,因為「the」在每個單詞的上下文中幾乎都會出現。
- 由於在文本中「the」這樣的常用詞出現機率很大,因此我們將會有大量的("the",…)這樣的訓練樣本,而這些樣本數量遠遠超過了我們學習"the"這個詞向量所需的訓練樣本數。
Word2Vec透過「子抽樣」來解決這種高頻詞問題。對於我們在訓練原始文本中遇到的每一個單詞,它們都有一定機率被我們從文本中刪掉,而這個被刪除的機率與單詞的頻率有關。
如果我們訓練採用的窗口大小為10(前5後5),並且從我們的文本中刪除所有的「the」,那麼會有下面的結果:
- 在訓練文本中剩下的其他字詞,"the"都不會是該字詞的鄰近詞;
- 對於每次輸入詞是"the"的情況下我們都可以少10次的訓練樣本(不用計算the跟其他鄰近詞的關係)。
這兩個效果將有助於減少樣本量、提高訓練速度,也可降低非攸關樣本造成的過擬合問題。
抽樣率
word2vec的C語言代碼便設計了一個計算在詞彙表中保留某個詞的機率公式。
ωi是一個單詞,Z(ωi) 是 ωi這個單詞在所有語料中出現的頻次。舉例而言,如果單詞「peanut」在10億規模大小的語料中出現了1000次,那麼 Z(peanut) = 1000/1000000000 = 1e – 6。
在代碼中還有一個參數叫「sample」,這個參數代表一個閾值,默認值為0.001。這個值越小意味著這個單詞被保留下來的機率越小(即有越大的機率被刪除)。
P(ωi) 代表著保留某個單詞的機率:
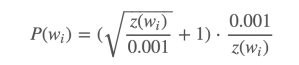
該機率公式畫出來的圖如下所示:
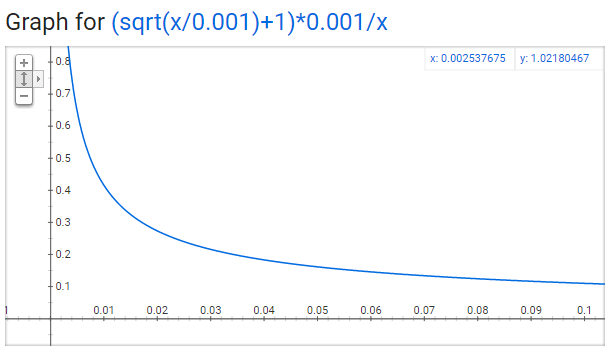
在語料庫裡裡應沒有任何一個單詞會佔據相當大的比例,故預期x軸應要是很小的數值。而y軸則是該單詞被保留的機率,故單詞出現的比例越高,該單詞被保留下來的機率越小。另外在這個計算式(sample值採用預設0.001)下有幾點值得一提:
● 當 P(ωi) = 1.0 。當單詞在語料中出現的頻率小於 0.0026 時,它是 100% 被保留的,這意味著只有那些在語料中出現頻率超過 0.26% 的單詞才會被採樣;
● 當 Z(ωi) = 0.00746 時,P(ωi) = 0.5,意味著這一部分的單詞有 50% 的機率被保留;
● 當 Z(ωi) = 1.0 時,P(ωi) = 0.033,意味著這部分單詞以 3.3% 的機率被保留。但這同時意味著整個語料庫都只有滿滿的ωi……
負採樣(negative sampling)
訓練一個神經網絡意味著要輸入訓練樣本並且不斷調整神經元的權重,從而不斷提高對目標的預測準確率。換句話說每當神經網絡經過一次訓練樣本的訓練,它的權重就會調整一次。
如上所述,字詞庫的大小決定了Skip-Gram神經網絡擁有很大或是非常大規模的權重矩陣,所有的這些權重需要通過我們數以億計的訓練樣本來進行調整,這是非常消耗計算資源的,並且實際中訓練起來會非常慢。
負採樣(negative sampling)解決了這個問題,它是用來提高訓練速度並且改善所得到詞向量的質量的一種方法。不同於原本每個訓練樣本更新所有的權重,負採樣每次讓一個訓練樣本僅僅更新一小部分的權重,這樣就會降低梯度下降過程中的計算量。
當使用訓練樣本 ( input word: “fox",output word: “quick") 來訓練神經網絡時,"fox"和"quick"都是經過one-hot編碼的。當字詞庫大小為10000時,在輸出層,我們期望對應"quick"單詞的那個神經元節點輸出1,其餘9999個都應該輸出0。這輸出為0的剩餘節點即為negative words。
當使用負採樣時,將隨機選擇一小部分的negative words(比如選5個negative words)來更新對應的權重。當然原本輸出為1的節點也應計入並更新對應權重。也就是說,從原本的10000個輸出層節點權重全部更新,改為僅更新6個節點的權重。
在論文中,作者指出對於小規模數據集,選擇5-20個negative words會比較好,對於大規模數據集可以僅選擇2-5個negative words。
在先前的範例中,隱藏層到輸出層要經過300 x 10000的權重矩陣。如果使用了負採樣的方法我們僅僅去更新我們的positive word也就是"quick"和我們隨機選擇的其他5個negative words的節點對應的權重,共計6個輸出神經元,相當於每次只更新 300 x 6 = 1800 個權重。對於3百萬的權重來說,相當於只計算了0.06%的權重,這樣計算效率就大幅度提高。
如何選擇negative words
使用「一元模型分布(unigram distribution)」來選擇"negative words"。
要注意的一點是,一個單詞被選作negative sample的機率跟它出現頻率有關,頻率越高的單詞越容易被選作negative words。
在word2vec的C語言實作中,可以看到對於這個機率的執行公式。每個單詞被選為「negative words」的機率計算公式與其出現的頻率有關。
代碼中的公式表示如下:
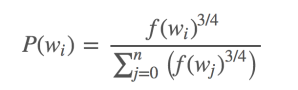
每個單詞被賦予一個權重,即 f(ωi), 它代表著單詞出現的頻次。
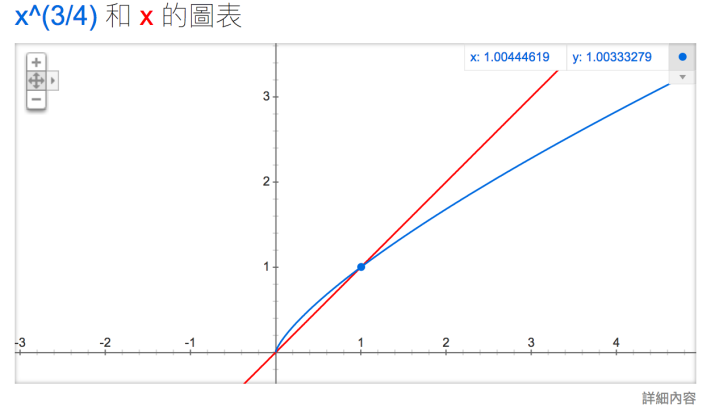
公式中開3/4的根號完全是基於經驗的,論文中提到這個公式的效果要比其它公式更加出色。你可以在google “plot y = x^(3/4) and y = x",可以看到x在[0,1]區間內時y的取值,x^(3/4) 有一小段弧形,取值在 y = x 函數之上。
參考資料來源:
http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/

非常有幫助,謝謝!
讚Liked by 1 person
解釋得非常清楚,謝謝!
讚Liked by 1 person